The UNESCO micro CDS/ISIS Software
Таблица выбора полей (ТВП) определяет критерии выбора одного или нескольких элементов из записей файла документов. В зависимости от программы, в которой используется ТВП, эти элементы могут затем использоваться для создания инвертированного файла для записи, из которой они были извлечены, для сортировки записей в желаемой последовательности перед выдачей отчетов на принтер или для переформатирования записей во время импортно-экспортных операций.
Элемент, обычно, определяется как фрагмент результирующей записи в определенном процессе. Хотя в большинстве случаев элементами в действительности являются элементы данных, т. е. поле или подполе, в других случаях это могут быть слова, фразы или другие фрагменты данных, которые имеют частный смысл для специфического применения.
Таблицы ТВП создаются или модифицируются средствами программы ISISDEF используя редактор строки системы CDS/ISIS (см. раздел 14 "Строковый редактор"). Пример ТВП, выдаваемой на экран редактором строк, показан на рис. 25.

Рис. 25
ТВП состоит из одной или более строк, каждая из которых определяется тремя параметрами :
Всякий раз, когда требуется выбрать элемент данных, используя ТВП, система прочтет соответствующие записи файла документов и выполнит для каждой записи и для каждого элемента ТВП следующие действия :
Процесс, описанный выше, является чисто механическим и выполняется точно так как описан. Он не передает информацию от одного шага к другому, а только данные о его обработке, хотя все шаги объединены в достижении желаемого результата. Например, тот факт, что определенное поле было выбрано на шаге1 неизвестно шагу 2 : шаг 1 используется языком форматирования для формирования строки символов и передается на шаг 2. Шаг2 обрабатывает строку символов в соответствии с указанной техникой индексирования. Техника индексирования определяется как обработка строки символов, но не записей или полей. Это является следствием общего назначения ТВП, которая может использоватся для таких различных целей, как определение содержимого инвертированного файла или спецификации требований по сортировке при печати, которые могут выглядеть, с первого взгляда, полностью несвязанными.
Для большинства примеров, можно воспринимать ТВП, как средство, позволяющее вызвать элементы данных, требуемые для выполнения определенных задач.
Три параметра строки ТВП описываются ниже в порядке их использования (при редактировании ТВП средствами редактора строки, они вводятся в определенном порядке).
Формат выбора данных кодируется используя средства языка форматирования описанного в разделе 8.3.5 "Формат печати". Так как данные, создаваемые этим форматом, не являются средством вывода на экран, а обрабатываются впоследствии, CDS/ISIS не ограничивает ширину строки каким-то определенным значением и следовательно данные никогда не будут разорваны на несколько строк. Понятие строк, однако, может быть релевантно определенной технике индексирования, выполняемой процедурой вывода по формату. В этом случае CDS/ISIS гарантирует, что строки будут создаваться только в ответ на команды новой строки, которые указываются в формате.
В связи с этим, большинство команд форматирования, такие как "С", смещение или escape - последовательность, будут обычно не связаны в формате выбора данных и могут в некоторых случаях выдывать непредсказуемые результаты. Поэтому их следует избегать, если нет особой необходимости.
С другой стороны режим (см. раздел 3.2.2 "Командный режим"), выбранный для ввода определенных полей, может быть средством для корректировки функционирования определенной техники индексирования : некоторые методы индексирования требуют явной спецификации режима (указывается в каждой технике индексирования, обсуждаемой ниже). Пользователь обязан указать соответствующие команды режима в формате выбора данных, если необходимо.
Заметим также, что требование перевода в заглавные буквы, может вызвать воздействие других дальнейших процессов, применяемых для выбора данных посредством ТВП. Как правило, не требуйте перевод в заглавные буквы (используйте режимы mpl, mhl, mdl чаще, чем mpu mhu mdu) до тех пор, пока вы не будете иметь каких-либо нежелательных эффектов. CDS/ISIS будет автоматически использовать перевод на режим заглавных букв при необходимости. Например, все элементы, сгенерированные посредством ТВП, будут переведены в заглавные буквы перед сохранением в словаре поисковых терминов, даже если в ТВП они были введены прописными буквами.
Техника индексирования указывает определенную обработку, которая будет выполнена с данными, выбранными по формату, в порядке указания элементов при создании ТВП. Существует пять методов индексирования. Каждому из них присваивается числовой код от 0 до 4, как объясняется ниже.
Создает элемент из каждой строки, извлеченной в соответствии с форматом. Данная техника обычно используется для индексирования целых полей или подполей. Заметим, что CDS/ISIS будет создавать элементы из строк, но не из полей. Это является следствием того, что CDS/ISIS воспринимает вывод по формату как строку символов, где поля не длиннее идентификатора. Поэтому, пользователь должен быть особо внимательным при вводе данных в формат, особенно при индексировании повторяющихся полей и/или более, чем одного поля. Другими словами, при использовании данной техники формат выбора данных должен выводить одну строку для каждого индексируемого элемента.
Создает элемент из каждого подполя или строки, выбранных по формату. Так как CDS/ISIS будет искать в выходном формате коды разделителей полей, для обеспечения правильной работы этой техники в формате должен быть использован проверочный режим (если режим не задан, то он используется по умолчанию), так как только в этом режиме сохраняются коды разделителей подполей при печати (необходимо помнить, что режимы заголовка и данных заменяют разделители подполей символами пунктуации). Заметим, что техника индексирования 1 в действительности сокращает использование техники индексирования 0. Пример использования этой техники приведен на рис. 26, который также показывает эффект использования режима данных.
Создает элемент из каждого термина или фразы, заключенные в угловые скобки < > . Любой текст вне скобок не индексируется. Обратите внимание, что данный метод требует проверочного режима, т. к. другие режимы удаляют скобки.
Пример:

Mission report descraibing a in at East African
даст следующие элементы при использовании данной техники:
< university course >
< documentation training >
< library school >
Выполняет те же операции, что и техника индексирования 2, за исключением того, что термины или фразы ограничиваются двумя косыми чертами (/.../). Например: mission report describing a / university course / in / document training / at an East African
/ library school / даст следующие элементы при использовании данной техники индексирования:
/ university course /
/ documentation training /
/ library school /
Создает элемент из каждого слова в тексте, выбираемого по формату. Словом является любая последовательность алфавитных символов.
При использовании этой техники, можно предотвратить индексирование некоторых незначащих слов, определив их в специальном файле, называемом файлом стоп-слов (см. раздел 17.3 "Создание файла стоп-слов", где описываются детали создания файла стоп-слов).
Обратите внимание, что при использовании данной техники для индексирования целого поля, содержащего разделители подполей, необходимо указать режимы заглавия или данных (MHL или MDL) в соответствующих форматах выбора данных, потому что замена разделителей подполя будет происходить перед индексированием и коды буквенных разделителей подполей будут считаться частью слова. Целесообразно использовать режимы заголовка и данных для индексирования полей, содержащих средства для изменения порядка сортировки,потому что только форма вывода поля на экран является индексируемой, а любые данные, требуемые для сортировки поля, игнорируются.
Идентификатор поля есть число (в пределах 1 - 32767), которое назначается каждому элементу, создаваемому на шаге индексирования. Значение идентификатора поля зависит от назначения использования ТВП, что объяснено ниже.
ТВП для инвертированного файла:
идентификатор поля предназначен для использования при поиске.
ТВП для сортировки:
идентификатор поля - это метка поля, которая используется при применении формата заголовка (см. раздел 8.3.4 "Формат заголовка").
ТВП для переформатирования:
идентификатор поля - это ISO метка поля, назначаемая для экс- порта поля (см. раздел 12.2.4.1 "Реорганизация ТВП") или CDS/ISIS метка, назначаемая для импорта поля.
Можно найти дополнительную информацию в ТВП, используемую для специального назначения см. раздел 8.5 "Системные рабочие листы для сортировки xYSRT", раздел 12.2 "Рабочий лист экспорта xYISI" и раздел 12.3 "Рабочий лист импорта xYISO".
Как указывалось раньше, одна ТВП для кажой базы данных определяет содержимое соответствующего инвертированного файла. Элементы данных, создаваемые по этой ТВП, однажды запомненные в инвертированном файле, составляют словарь поисковых терминов для данной базы данных. Одного словаря, однако, недостаточно, чтобы обеспечить механизм поиска, т. е. каждый термин должен быть связан со всеми записями базы данных, в которых он имеется. Таким образом, для каждого поискового термина в словаре CDS/ISIS определяет список "регистраций", обеспечивающий такую связь. Каждый термин имеет столько регистраций, сколько раз он встречается в базе данных.
Более того, чтобы обеспечить такие сложные средства языка поиска, как операторы близости, каждая "регистрация" содержит не только МFN записи, но и дополнительную информацию о расположении термина в записи, из которой он был выбран.
Регистрация имеет четыре компоненты:
Например, термин IT может быть либо местоимением (в таком случае он будет менее используемым при поиске), либо кодом страны ITALY. Он может также соответствовать цифровым терминам, таким как 34, значение которого может быть непонятным при его выборе из контекста.
Если поле, создаваемое такими терминами, индексируется с помощью техники 0, можно добавить смысл, используя префикс-литерал для указания метки, которая будет затем идентифицировать определенное использование термина. Например, когда индексируется поле, содержащее код страны, т. е. v10, можно использовать следующий формат: "КС = " v10 (правильнее чем v10), потому что код страны IT будет инвертирован как КС = IT (правильнее чем только IT ). Аналогично, если поле 20 содержит номер проекта, можно использовать формат "Проект", v20, для того чтобы потом можно осуществлять поиск Проект34 ( вернее, чем только 34).
На рис. 27 показана обработка ТВП данной на рис. 25, применяемой к записи, показанной на рис. 6. Рис. 28 показывает полную "регистрацию", назначаемую каждому элементу перед сохранением в инвертированном файле. На рис. 29 показаны элементы и соответствующие "регистрации", которые будут инвертироваться при использовании файла стоп-слов ( см. раздел 17.3 "Создание файла стоп-слов"). Необходимо отметить, что хотя стоп-слова не выводятся на экран, они учитываются в числовой последовательности терминов.
В этой главе описывается метод проверки ТВП, которая определяет содержимое инвертированного файла. Здесь прослеживаются все шаги, начиная с первого момента создания ТВП. Кроме того, дается возможность лучше понять функционирование ТВП. По мере приобретения опыта, появится возможность пропускать большинство этих шагов. Однако, желательно делать некоторые предварительные проверки перед полным инвертированием базы данных, особенно, если эта база большая.
1. Введите несколько записей в базу данных. Они должны быть подобраны таким образом, чтобы отражать все возможные варианты действительного содержания базы данных. Если возможно, используйте реальные данные. В этом случае появится возможность проверить существующий рабочий лист и посмотреть, достаточно ли правильно он создан для использования различных типов записей.
2. Имея под рукой распечатку ТВП, можно проверить каждый формат выбора данных. Используя средства программы ISISRET, выполните следующие действия:
а) выберите опцию F и введите формат выбора данных ТВП;
в) выберите опцию В и посмотрите полученный вывод по формату;
с) мысленно примените используемую технику индексирования к полученному выводу на экран и уточните предполагаемый результат, в частности проверка сводится к следующему:
* если вы применяете технику индексирования 0 к повторяющемуся полю, находится ли каждое значение поля на отдельной строке?
* если вы применяете технику 4 к повторяющемуся полю, указан ли знак % определяющий каждое значение поля (если нет, вы будете не в состоянии использовать (F) оператор поиска, потому что CDS/ISIS будет назначать один и тот же номер значения каждому слову и обратится ко всем значениям, как к единому полю);
* если вы применяете технику 2, ограничен ли каждый термин на экране угловыми скобками? (если нет, убедитесь, что ваш формат не потребует никакого другого режима вывода на печать, кроме проверочного режима, т. к. угловые скобки выводятся на экран только в проверочном режиме);
* если вы применяете технику 1, указаны ли на экране разделители подполей? (если нет, убедитесь, что использован проверочный режим);
d) если вы предполагаете какие-то ошибки в формате, повторите шаги (а) - (с), сделав необходимые изменения в формате;
е) повторяЙте шаги (а) - (d) для каждой строки ТВП до тех пор, пока полностью не убедитесь в том, что форматы являются правильными. Если вы изменили какой-то из форматов, проверьте все изменения, которые вы сделали или лучше распечатайте содержимое экрана на бумагу.
3. Если необходимо, выберите программу ISISDEF и модифицируйте форматы в существующей ТВП согласно замечаний, полученных на шаге 2 (е).
4. Затем выберите программу ISISINV, укажите опцию G из меню xXG1 и установите ограничения МFN для инвертирования только нескольких записей.
5. Когда связи файлов созданы, выйдите из программы ISIS и напечатайте содержимое файлов хххххх. LN1 xxxxxx. LN2 (где хххххх - имя базы данных). Эти файлы содержат все поисковые термины, которые были созданы для каждой записи: являются ли они правильными? Если нет, значит существует какая-то ошибка в вашей TBП. Повторите шаги 1 - 5 до получения необходимого результата.
Как упоминалось выше, по мере совершенствования знаний языка форматирования, вы можете пропустить шаги 4 и 5 перед попыткой полного инвертирования новой базы данных.
Хотя программа ISISDEF позволяет модифицировать ТВП после ее создания, необходимо помнить, что некоторые изменения ТВП для инвертированного файла потребуют последующего переинвертирования базы данных, т. к. инвертированный файл, созданный по старой ТВП, не будет больше соответствовать элементам, созданным с помощью измененной ТВП.
В основном переинвертирование требуется в том случае, когда нужно выполнить одно или более следующих изменений:
яизменить технику индексированияя: сгенерированные элементы будут полностью отличаться, если две различные техники индексирования применяются к одинаковым данным;
ядобавить или удалить строки в ТВПя: удаление строки в ТВП без перегенерирования инвертированного файла оставляет в словаре термины, которые были сгенерированы в нем и могут быть найдены при поиске; добавление строки без перегенерирования инвертированного файла не будет вызывать доступ к существующим записям при поиске по новой строке ТВП. Заметим, что добавление нового элемента, соответствующего полю, которое ранее не существовало, не требует переинвертирования;
яизменить формат выбора данныхя: элементы, индексируемые по новому формату будут отличаться от сгенерированных по старому формату;
яизменить идентификатор поляя: хотя термины словаря будут оставаться теми же, идентификатор поля, запомненный в регистрациях этих терминов при создании инвертированного файла будет отличаться.

Рис. 27
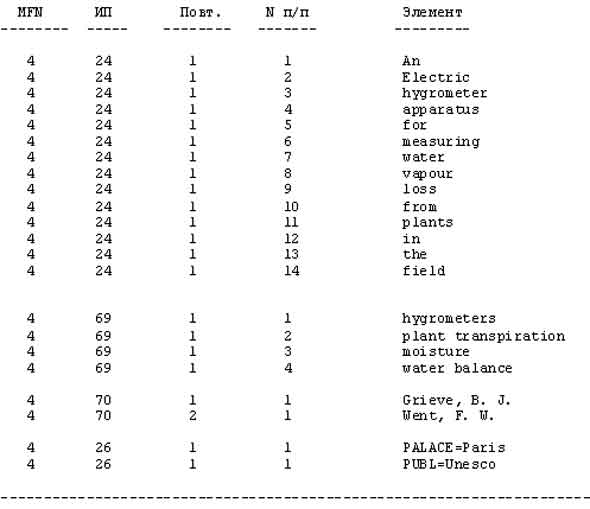
Рис. 28
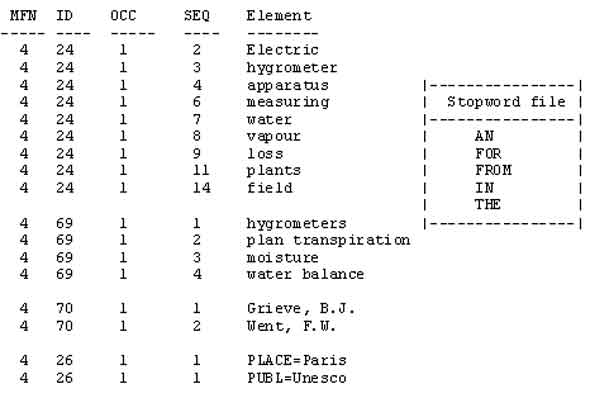
Рис. 29
Всі права захищено ©
2013 - 2026 Національна бібліотека України імені В. І. Вернадського
Працює на Drupal | За підтримки OS Templates


Ми в соціальних мережах